Run frontier AI entirely
on your own hardware.
Cube AI is Ultraviolet's flagship platform for private LLM deployment — inference, retrieval, guardrails, governance, and a production workspace, all inside your perimeter. Nothing leaves your network.
The complete operating environment for private, sovereign AI.
Cube AI gives regulated and sovereign organizations everything they need to build and run AI without sending a single byte to a third party. Open models serve from your own GPUs, retrieval runs over your own knowledge bases, and every prompt is policed by your guardrails and recorded in your audit trail.
It is the flagship of the Ultraviolet ecosystem — the product most teams start with, and the one the rest of the stack is built to support.
One platform, top to bottom of the stack.
Cube AI bundles everything an organization needs to operate AI privately: model serving, retrieval, policy enforcement, and governance — all running on the same confidential-computing substrate as the rest of Ultraviolet.
Everything you need to
operate AI in production.
Cube AI is not a model — it is the full platform around your models: serving, retrieval, safety, governance, and the interfaces your teams actually use.
Private inference
vLLM and Ollama runtimes serve open models on your own GPUs — no API keys, no egress, no rate limits but your own.
RAG on your data
Generate embeddings inside the environment and connect internal knowledge bases with retrieval that never copies a byte off-premises.
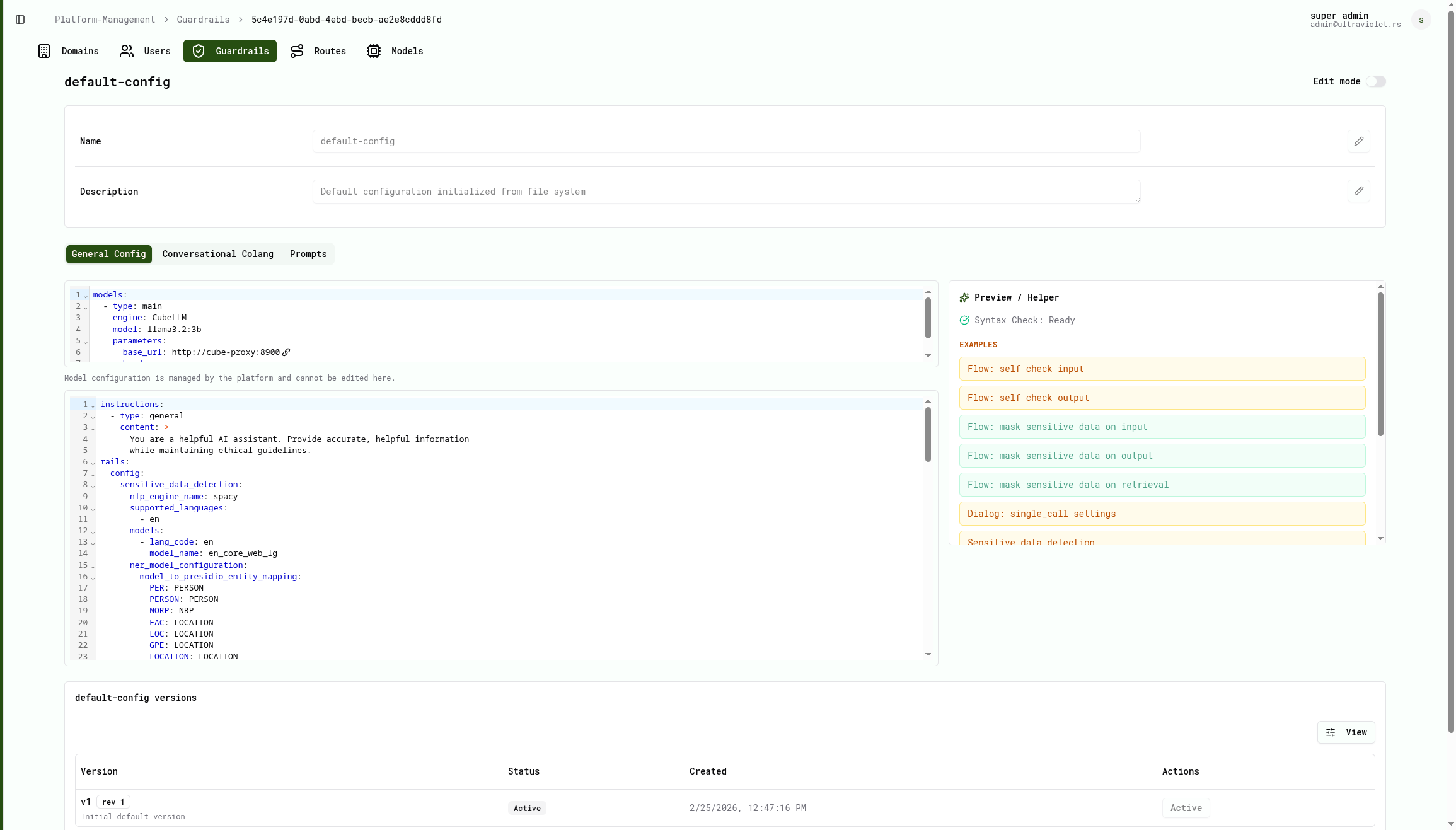
Guardrails & PII redaction
NeMo guardrails, prompt-injection defense, output sanitization, and automatic PII redaction via Microsoft Presidio on every call.
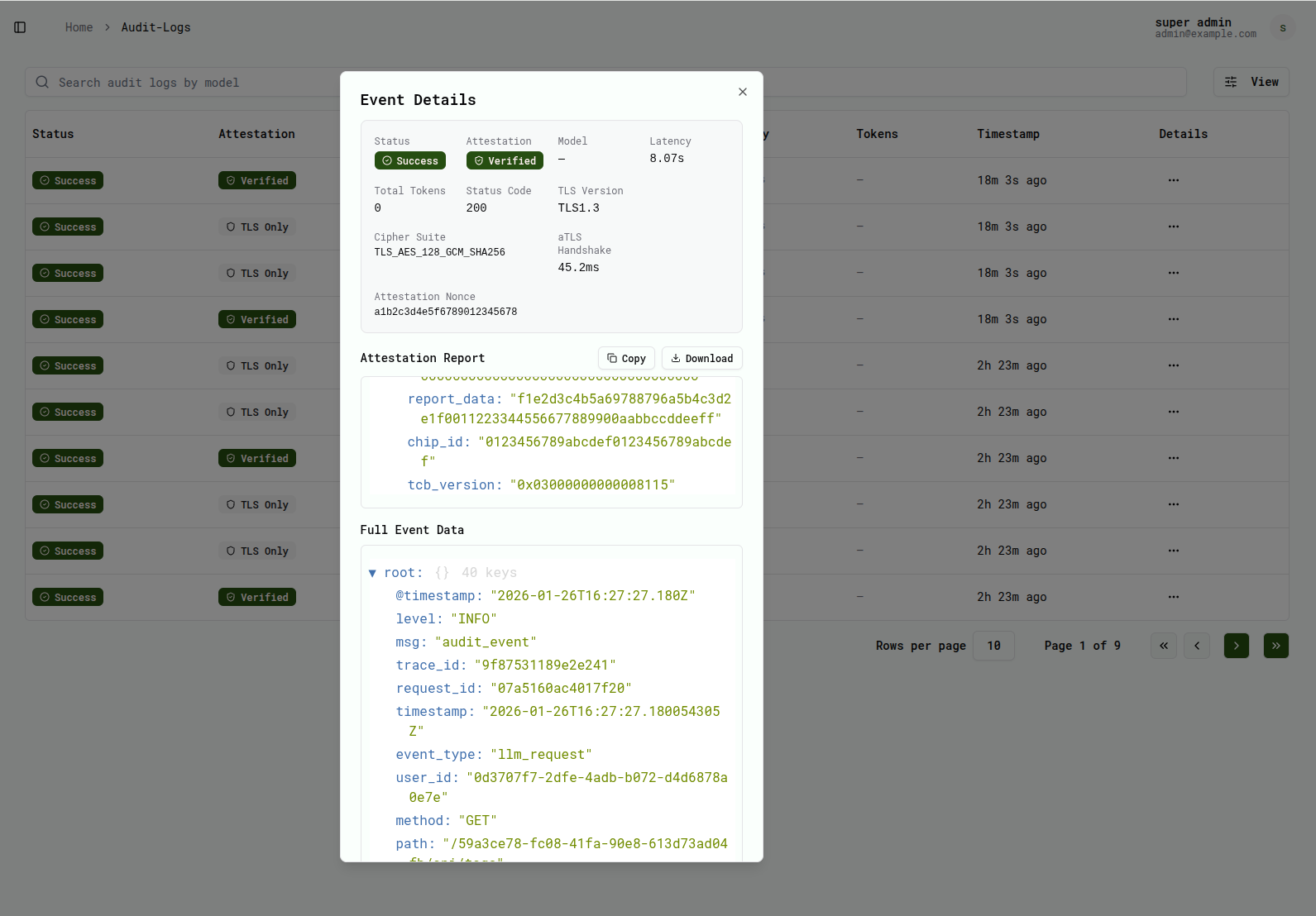
Governance & audit
Full audit trail, role-based access, and per-domain usage accounting built in.
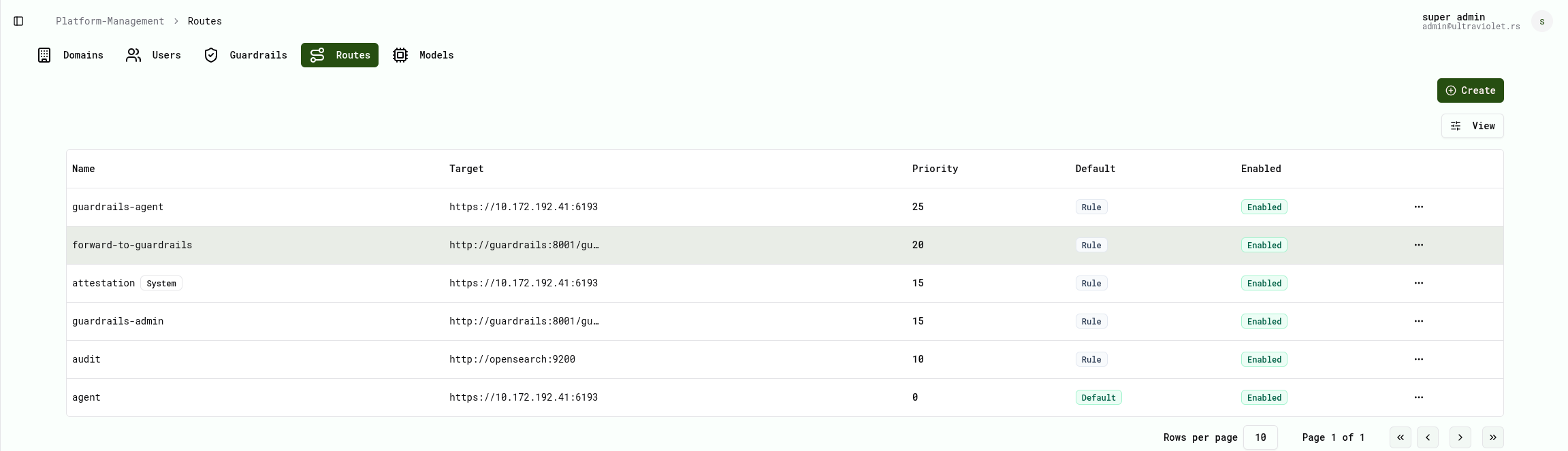
Model management
Register, version, and route across open models — Llama, Mistral, Qwen, DeepSeek, Phi, Gemma — from one control plane.
Hardware TEE
Run the whole stack inside AMD SEV-SNP or Intel TDX enclaves — weights and tensors stay encrypted in use, even from the host.
Multi-tenancy & domains
SuperMQ-backed domain isolation gives every team or tenant a strictly separated workspace with its own identity and policies.
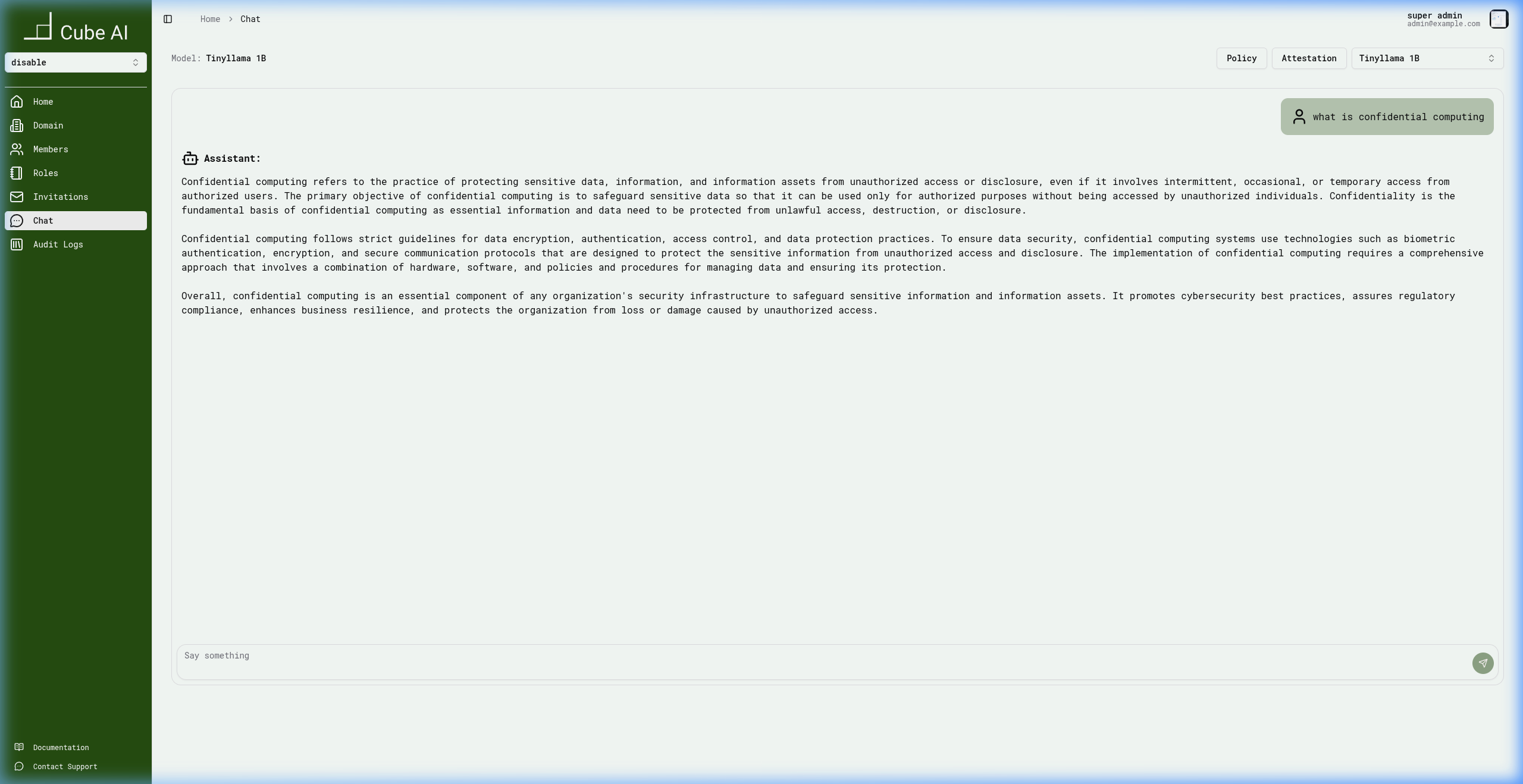
Secure chat
An end-to-end encrypted chat workspace backed by verifiable hardware attestation for everyday private AI.
OpenAI-compatible API
OpenAI-compatible endpoints and SDKs drop Cube AI into the apps and agents you already run.
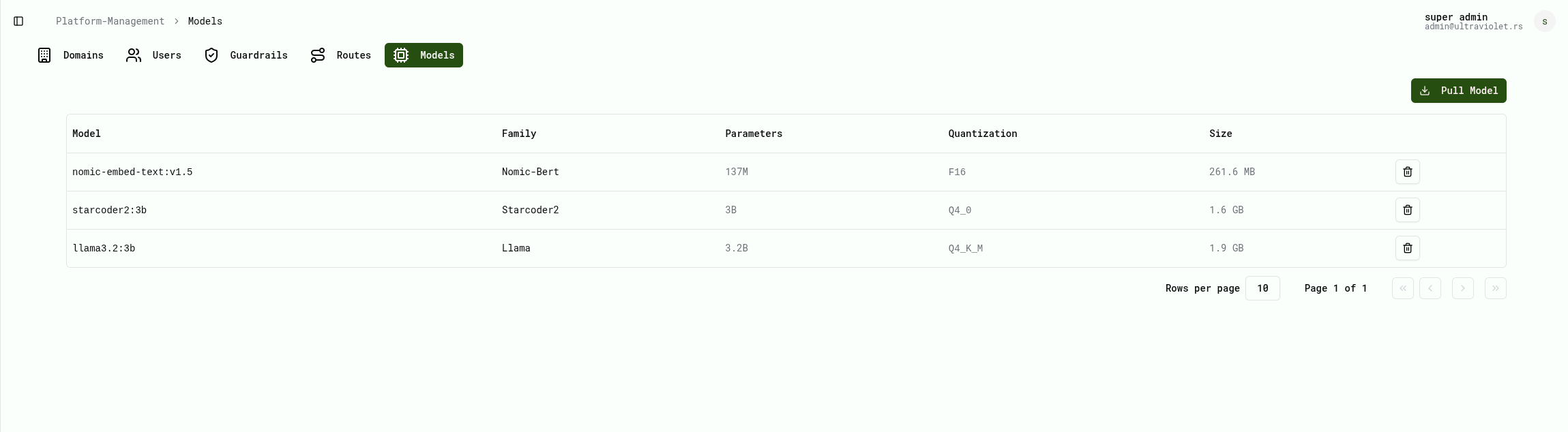
A production workspace,
not just an endpoint.
Cube AI ships with the interfaces your teams actually use — operations, model management, safety, audit, and chat. Pick a surface to see it.
The models you choose,
on the hardware you own.
Cube AI is model-agnostic and infrastructure-agnostic. Serve open-weight models through the runtime that fits your workload, on everything from a single GPU to an air-gapped confidential cluster.
Plugs into the tools
your developers already use.
Because Cube AI speaks the OpenAI API, it slots into existing developer workflows — IDEs, agents, and SDKs — while keeping every prompt inside your perimeter.
Continue
AI-assisted coding inside VS Code and JetBrains, served by your own private Cube models — autocomplete and chat with zero IP leakage.
Read the docsOpenCode
Point the OpenCode terminal agent at Cube for confidential, in-perimeter pair-programming on your own infrastructure.
Read the docsOpenAI-compatible API
Drop-in OpenAI-compatible endpoints mean the OpenAI SDK, LangChain, and custom HTTP clients all work unchanged — just repoint the base URL.
Read the docsWherever your data has to live,
your AI can run.
On-premises
Run on your own servers and GPUs, behind your firewall, under your change control.
Questions teams ask
before they deploy.
What is Cube AI?
Cube AI is a self-hosted platform for running large language models privately. It bundles inference, retrieval-augmented generation, guardrails, governance, audit, and a production UI into one stack that runs entirely on infrastructure you control.
How is it different from a hosted API like OpenAI or Anthropic?
With a hosted API, your prompts and data leave your organization and are processed in someone else's cloud and jurisdiction. Cube AI runs inside your own perimeter — on-prem, air-gapped, or in a sovereign cloud — so data never leaves, and you own the models, the policies, and the audit trail.
Which models can I run?
Cube AI is model-agnostic. It serves open-weight models such as Llama, Mistral, Qwen, DeepSeek, Phi, and Gemma — plus custom fine-tunes in GGUF or safetensors format — through vLLM, Ollama, and Hugging Face, all from a single control plane.
Where can I deploy it?
Anywhere your data has to live: on-premises behind your firewall, fully air-gapped for classified environments, in an EU or national sovereign cloud, in your own private VPC, or at the edge — with the same governance everywhere.
What are guardrails?
Guardrails are policy rules that sit between your users and the model — inspecting every prompt and response before it is processed or returned. They can block harmful inputs, detect prompt-injection attempts, filter profanity or off-topic requests, and enforce domain-specific rules your organization defines.
How do guardrails work in Cube AI?
Cube AI uses NVIDIA NeMo Guardrails as its policy engine, augmented with Microsoft Presidio for automatic PII detection and redaction. You author guardrail configurations as YAML-based Colang rules through the Cube dashboard — no code required. Rules hot-reload with zero downtime, and every guardrail decision is recorded in the audit trail so you can see exactly what was allowed, blocked, or redacted on every call.
What is a Trusted Execution Environment (TEE)?
A TEE is a hardware-isolated region inside a CPU — such as an AMD SEV-SNP confidential VM or an Intel TDX Trust Domain — where code and data are encrypted in memory at all times. Even the hypervisor and the host OS cannot read the contents. Remote attestation lets you cryptographically verify that the correct, unmodified software is running inside the enclave before trusting it with sensitive data.
How do I enable TEE support in Cube AI?
Deploy Cube AI on a host with AMD SEV-SNP or Intel TDX hardware — available on several cloud providers and on-prem servers. Cube AI runs on top of Cocos AI, Ultraviolet's open-source confidential-computing layer, which handles enclave provisioning, remote attestation, and key management automatically. Once running inside a TEE, every model weight, prompt, and response is encrypted in use, and clients can verify the enclave before sending any data.
Is Cube AI open source?
Yes. The core is Apache 2.0. You can inspect the source, fork it, and run it indefinitely with no vendor lock-in. Commercial support and enterprise features are available from Ultraviolet.
Part of the Ultraviolet
sovereign AI stack.
Three products, designed to work as one. Each runs on the same confidential-computing foundation, shares the same governance model, and deploys anywhere your data must live.
Cube AI
Full-stack private LLM platform — inference, RAG, guardrails, governance, audit.
You are herePrism AI
Run joint AI workloads across organizations without exposing any party's data.
Explore Prism AICocos AI
The open-source TEE abstraction layer the rest of the stack is built on.
Explore Cocos AIBring frontier AI inside
your perimeter.
Talk to the team about pilots, deployment architectures, and regulated-industry rollouts — on your hardware, on your terms.